Read XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition Online
Authors: Michael Kay
XSLT 2.0 and XPath 2.0 Programmer's Reference, 4th Edition (681 page)

Using the
The defaulting mechanisms ensure that it is usually not necessary to include an
element, in which case either the HTML or the XHTML output method is used, depending on the namespace.
The
The
encoding
attribute can be very useful to ensure that the output file can be easily viewed and edited. Unfortunately, though, the set of possible values varies from one XSLT implementation to another, and may also depend on the environment. For example, many XSLT processors are written in Java and use the Java facilities for encoding the output stream, but the set of encodings supported by each Java VM is different. However, support for iso-8859-1 encoding is fairly universal, so if you have trouble viewing the output file because it contains UTF-8 Unicode characters, setting the encoding to iso-8859-1 is often a good remedy, at least if your document is written in a Western European language.
If your stylesheet generates accented letters or other special characters, and it looks as if they have come out incorrectly in the output, chances are they are correctly represented in UTF-8, but you are looking at them with a text editor that doesn't understand UTF-8. Either select a different output encoding (such as iso-8859-1), or get a text editor such as jEdit (
www.jedit.org
) that can work with UTF-8. If the problem occurs when you view the file in a browser, the most likely explanation is that the
element gives the wrong
charset
.
The
encoding
attribute determines how the XSLT processor serializes the output as a stream of bytes, but it says nothing about what happens to the bytes later. If the processor writes to a file, the file will probably be written in the chosen encoding. But if the output is accessed as a character string through an API, or is written to a character field in a database, the encoding of the characters may be changed before you get to see them. A classic example of this effect is the Microsoft
transformNode()
interface (see Appendix D), which returns the result of the transformation as a
BSTR
string. Because this is a
BSTR
, it will always be encoded in UTF-16, regardless of the encoding you request. The same thing will happen with the JAXP interface (see Appendix E); if you supply a
StreamResult
based on a
Writer
, the encoding then depends on how the particular
Writer
encodes Unicode characters, and the XSLT processor has no control over the matter.
Character Maps
A character map is used during serialization when it is named in the
use-character-maps
serialization attribute. This is a list of named character maps; these character maps are concatenated in the order that they are listed, and any conflicts are resolved by choosing the mapping for a character that is last in the list.
During serialization, character mapping is applied to characters appearing in the content of text nodes and attribute nodes. It is not applied to other content (such as comments and processing instructions), nor to element and attribute names. It is not applied to characters for which
disable-output-escaping
has been specified, nor to characters in
CDATA
sections (that is, characters in the content of elements listed in the
cdata-section-elements
serialization parameter). In the case of the HTML and XHTML output methods, character mapping is applied to characters in URI-valued attributes after they have been subjected to URI escaping under the rules of the HTML and XHTML output methods, and it is also applied to attributes in a generated
element.
If a character is included in the character map, this bypasses the normal XML/HTML escaping, as well as Unicode normalization. For example, if a character map causes the character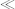 ∧
∧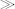 to be replaced by&&, then it will be output as&&, not as&&, even though the result is invalid XML.
to be replaced by&&, then it will be output as&&, not as&&, even though the result is invalid XML.
The final stage of serialization is character encoding (as determined by the encoding parameter). This converts logical Unicode characters into actual bytes or octets; for example, if the encoding is UTF-8 then the characterÇwill be represented by the two octetsx3c xA7. You cannot use character maps to alter the effect of the character encoding process.
